声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Phonological Features for 0-shot Multilingual Speech Synthesis
该文章是在2020.08.06更新的文章,该文章主要做0-shot的情况下依然可以合成出来,该文章出发点和以前研究multilingual TTS不同之处:使训练集中没有出现的音素依然可以合成。具体文章链接https://arxiv.org/pdf/2008.04107.pdf
1 研究背景
多语言模型需要设计输入格式,使其多种语言共用一套。常用的方法是使用多种语言的音素作为一个集合并进行编码,该方法缺点是当添加新的一种语言就要添加不同的音素集进来,而且训练集中不存在的音素则不能发音。另一种方法是使用unicode byte进行编码,不考虑语音特征,这样对新的语言进行迁移学习时候,看不见的字符组合需要重新学习(使用byte还没做过实验,看过的文章都写不好)。本文章针对以上问题,设计了基于国际音标IPA语音特征的输入方式,使其可以在多语言模型上进行新的语言迁移学习,即使没出现的音素也可以合成。
2 具体方案
这里我讲下文章的主要思想,本文为了使多语言能够进行统一格式输入,因此选择国际音标IPA作为统一输入集,然后把IPA转成具有诸多特征的语音特征。该特征包括(consonant/vowel, voicing (voiced/unvoiced), vowel frontness, vowel openness, vowel roundedness, stress on vowel, consonant place, consonant manner, and diacritic (e.g., nasalised, velarised). )整体过程为:多语言的音素集--->IPA--->语音特征phonological features。具体的转换脚本为代码库:https://github.com/papercup-open-source/phonological-features
3 实验
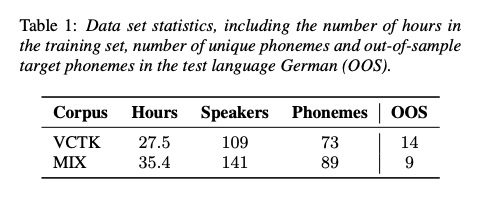
本文实验是在tacotron2上进行,本处不在进行讲解。基础模型数据库(VCTK, MIX(英语vctk & 西班牙语adrianex)),迁移目标数据为德语,数据的情况为table 1。其中oos为未覆盖的音素集
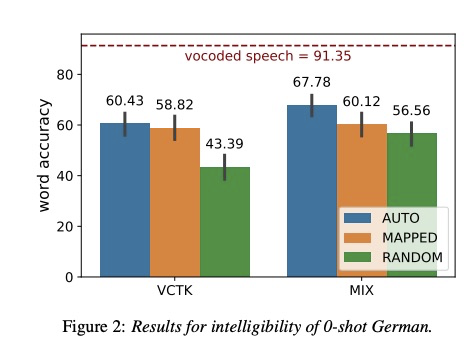
实验的对比系统:RANDOM:对oos的音素的embedding随机赋值;MANUAL为把oos音素跟基础模型的音素根据语音特征计算距离,选取距离较短的音素值赋值给该因素。本文的方案为AUTO。
首先看一下图1,子图(a)为baseline的音素分布,音素之间没有形成聚类 (b)为本文方案,音素之间有聚类现象 (c)为oss的音素可以寻找到相似的音素集群中

在音质可懂度方面,图2显示本文的方案可懂度最好。
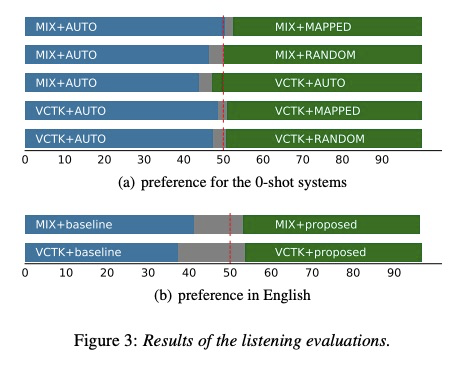
在AB偏爱的比较之间则没有特别的好坏之分。
4 总结
本文使用基于国际音标IPA的语音特征作为输入,在新的语言中没出现的音素也可以生成。