来源:so.csdn.net
发布时间:Dec 3, 2020, 2:18:43 PM
原地址:https://blog.csdn.net/weixin_45732418/article/details/110563319
简介:
opensmile工具是比较简单的提取语音特征文件的方法之一,一般用来对语音文件(*wav)来提取特征用来训练模型,那么opensmile如何调用,具体代码内容的理解以及结果示意
代码:
#包的引入 这些包python自带
import os
from subprocess import call
#路径设置
#SMILExtract_Debug.exe所在的文件路径
pathExcuteFile = r'D:\....\.....\.....\SMILExtract_Debug.exe'#不是要求路径具体大小 省略号就是简单省略
#opensmile配置文件所在的路径 一般根据要求会选择不同的配置文件
pathConfig = r'/.../..../.../...*conf'
pathAudio = r'path' #该目录下是各个类别文件夹,类别文件夹下才是wav语音文件,比如说,我把wav文件放在了voice的文件夹里,但是voice在new文件夹里 所以应该具体到new文件夹即可,因为下面的代码是对整个文件夹里的所有文件目录里的文件进行操作,具体适用于多种不同类型的语音来进行提取特征
pathOutput = r'输出目录'#这里的路径可以自行设置比如"...\\...\\"python要加一个\转义字符
#利用cmd调用exe文件
def excuteCMD(_pathExcuteFile,_pathConfig,_pathAudio,_pathOutput):
cmd = _pathExcuteFile + " -C "+ _pathConfig +" -I "+ _pathAudio + " -O " + _pathOutput
call(cmd, shell=True)
def loopExcute(pathwav,patharff): # 子目录,对目录里所有wav目标文件进行处理
for category in os.listdir(pathwav):
category_path = os.path.join(pathwav,category)
for file in os.listdir(category_path):
if os.path.splitext(file)[1] == '.wav':
file_path = os.path.join(category_path,file)
name = os.path.splitext(file)[0]
outputname = 'all_test.arff'#这里是将所有的特征文件写道一个arff文件里,也可以用一个一直在变的名称来实现一个语音对应一个特征文件
output_path = os.path.join(patharff,outputname)
excuteCMD(pathExcuteFile, pathConfig, file_path, output_path)
if __name__ == '__main__':
#excuteCMD(pathExcuteFile, pathConfig, pathAudio, pathOutput)
loopExcute(pathAudio, pathOutput)
#提取特征比较长,要耐心等待
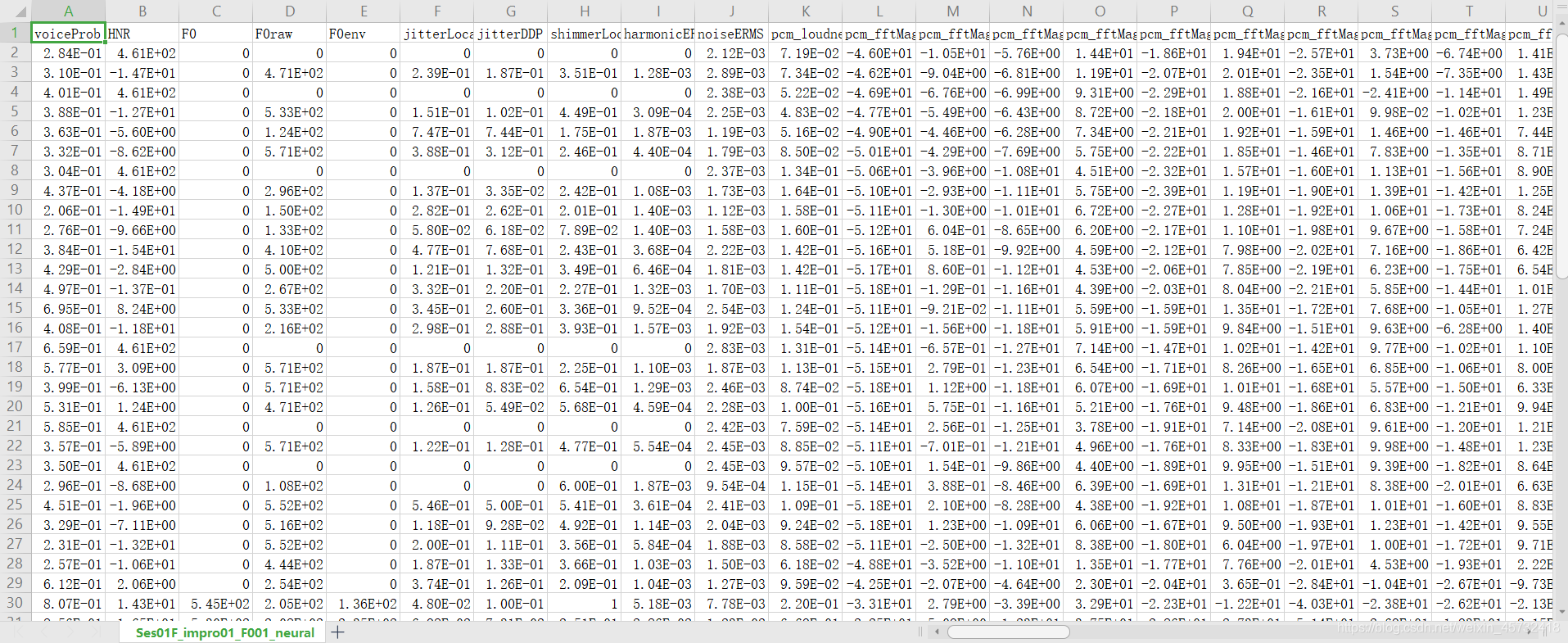
文件展示
arff: 不同配置文件的呈现形式一般不一样
不同配置文件的呈现形式一般不一样
csv:
后续更新:
特征文件具体用来作为训练模型的输入数据,那么对于分类最简单的训练工具便是libsvm,那么怎么将生成的arff特征文件(特征文件还可以是csv或者txt等类型文件)变成符合libsvm文件输入的特征文件格式?