声明:工作以来主要从事TTS工作,工程算法都有涉及,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 http://yqli.tech/page/tts_paper.html TTS 开源数据 http://yqli.tech/page/data.html。如转载,请标明出处。
欢迎关注微信公众号:低调奋进
目录
1 标贝
2 希尔贝壳
3 DiDiSpeech
4 LJ speech Dataset
5 VCTK
6 LibriTTS
7 CSS10
语音合成系统的训练需要大量高质量精标语料库,这给很多研究人员带来诸多不便。本篇文章主旨为整理目前开源的语音语料,便于相关从业者使用。首先,我们需要为这些为开源数据做贡献的个人、公司或者组织表达敬意,有了这些开源的数据,才能促进语音合成的发展。
我把个人搜集的语音合成、语音识别和噪声数据整理到个人的网站,有兴趣的研究者可以搜藏 http://yqli.tech/page/data.html
本文章对开源的语音合成数据的选取的标准:音频的质量较高,语料库包含音频和对应的标注信息文件。
标贝
标贝(北京)科技有限公司(简称“标贝科技”)是一家专注智能语音交互和AI数据服务的人工智能公司,为AI领域提供各种高质量的训练语料和技术方案。标贝开源了一万句的女生音库,详细信息如下:
数据内容:中文标准女声语音库数据
录音语料:综合语料样本量;音节音子的数量、类型、音调、音连以及韵律等进行覆盖。
有效时长:约12小时
平均字数:16字
语言类型:标准普通话
发音人:女;20-30岁;声音积极知性
录音环境:声音采集环境为专业录音棚环境:1)录音棚符合专业音库录制标准;2)录音环境和设备自始至终保持不变;3)录音环境的信噪比不低于35dB。
录制工具:专业录音设备及录音软件
采样格式:无压缩PCM WAV格式,采样率为48KHz、16bit
标注内容:音字校对、韵律标注、中文声韵母边界切分
标注格式:文本标注为.txt格式文档;音节音素边界切分文件为.interval格式
质量标准:1. 语音文件为48k 16bit wav格式,音色、音量、语速一致,无漂零无截幅;2.标注文件字准率不低于99.8%;3.音素边界错误大于10ms的比例小于1%;音节边界准确率大于98%.
存储方式:FTP存储
文件格式:音频文件:WAV 文本标注文件:TXT 边界标注文件:INTERVAL
版权所有者:标贝(北京)科技有限公司
想使用该数据的用户请访问链接
https://www.data-baker.com/open_source.html
Aishell 希尔贝壳
北京希尔贝壳科技有限公司成立于2017年,是一家专注人工智能大数据和技术服务的创新公司。本次开源的中文普通话语音数据库AISHELL-3的语音时长为85小时88035句,可做为多说话人合成系统。录制过程在安静室内环境中, 使用高保真麦克风(44.1kHz,16bit)。218名来自中国不同口音区域的发言人参与录制。专业语音校对人员进行拼音和韵律标注,并通过严格质量检验,此数据库音字确率在98%以上。(支持学术研究,未经允许禁止商用。)数据参数如下:

想使用该数据的用户请访问
DiDiSpeech
DidiSpeech是一个针对中文个性化语音合成任务的大规模数据库。该数据库提供了由超过6000名说话人录制的近800小时的语音数据。此次第一批开放数据为500人,时长60余小时的语音数据。
数据库中所有的音频均由说话人使用手机在安静环境中录制,具有较高的语音质量。同时,数据库中的说话人在性别、年龄以及地域等方面分布均匀,具有充足的多样性。在录制文本的设计上,数据库分别设计了平行文本与非平行文本,以确保在音色转换、多说话人语音合成等任务上数据的高度可用。此外,所有录制文本提供了注音标注。数据特点如下图。
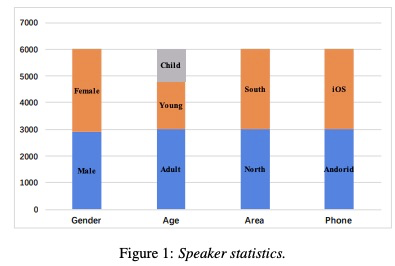
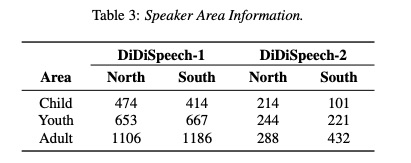
该数据需要申请,所以想使用的用户可以申请(吐槽一下,申请那么麻烦,就不能学习一下希尔贝壳吗,这很不open,即想**,又想立**!太麻烦我就没申请)
https://outreach.didichuxing.com/research/opendata/
LJ speech Dataset
本音库为一位英语女生说话人,一共13100条数据,共24小时。音频参数为16bit, 22khz。具体的参数如下:
| Total Clips |
13,100 |
| Total Words |
225,715 |
| Total Characters |
1,308,678 |
| Total Duration |
23:55:17 |
| Mean Clip Duration |
6.57 sec |
| Min Clip Duration |
1.11 sec |
| Max Clip Duration |
10.10 sec |
| Mean Words per Clip |
17.23 |
| Distinct Words |
13,821 |
想使用该数据的用户请访问
https://keithito.com/LJ-Speech-Dataset/
VCTK
本音库为多说话人英语语料,该音库有不同口音的109位英语发音人,每位发音人大约400句话,其内容主要来自报纸,彩虹段落和语音口音档案中使用的启发段落。所有音频记录为16bit,48khz。
想访问该数据的用户请访问
https://datashare.is.ed.ac.uk/handle/10283/2651
LibriTTS
LibriTTS是多说话人英语语料,大约有585小时,根据音频质量分为好几个子集,用户可以根据需要进行选择使用,(音质不是太高,可以用于speaker encoder训练使用)具体参数如下
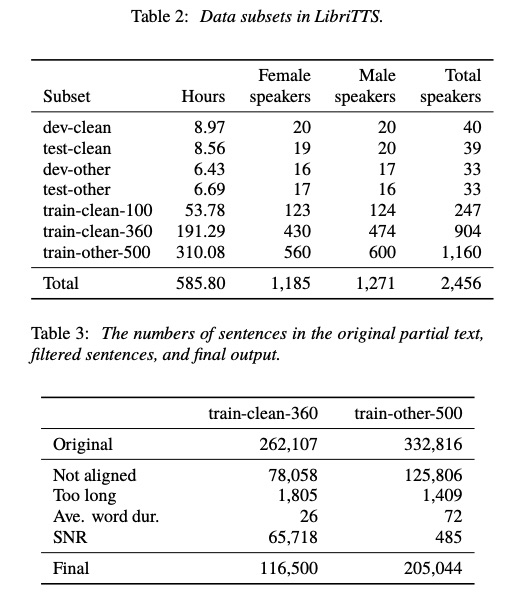
想访问该数据的用户请访问
CSS10
数据提供了德语,希腊语,西班牙语,法语,中文,日语,俄罗斯,芬兰,匈牙利语,荷兰语等10种语言,(音质不是太高),具体的参数如下:
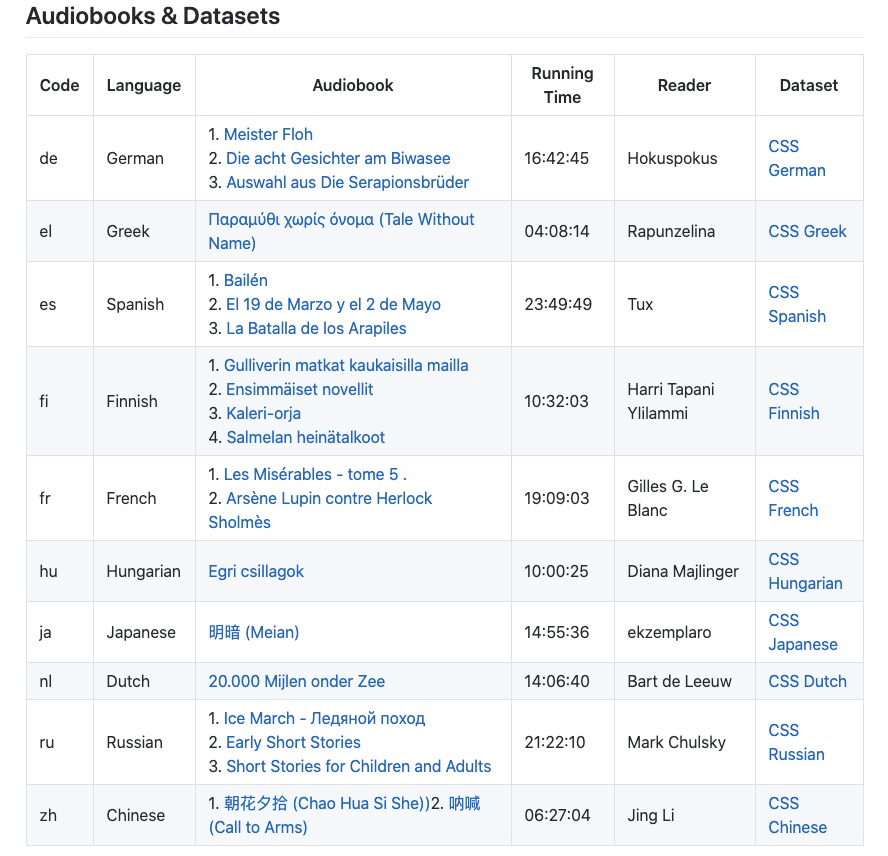
想访问该数据的用户请访问
https://github.com/Kyubyong/css10
其它的语音识别,语音合成等开源数据可参考道友整理的数据库
http://yqli.tech/page/data.html
https://github.com/JRMeyer/open-speech-corpora
https://github.com/KuangDD/zhvoice