声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Accent and Speaker Disentanglement in Many-to-many Voice Conversion
本文章是2020.11.17西北工业大学,爱奇艺和标贝联合发表的文章,主要做many-to-many的带口音的VC(声音转换),具体的文章链接如下
https://arxiv.org/pdf/2011.08609.pdf (我听了demo,还算可以,但总感觉音质方面不太高)
1 研究背景
VC(voice conversion)是保持语言内容但音色转换成另外一个人的声音(比如柯南的变声器),AC(accent conversion)是保持语言内容和说话人的音色,但口音发生变化(如把标准普通话转成天津话,四川话等发音方式)。目前通用的流程,是先通过ASR模型把语音转成与说话者无关的中间表现形式,比如PPG(phonetic posteriorgram)或者BN(bottleneck feature)等(目前这两种表现形式我也正在进行,因为我做跨语言,所以重新训模型很慢)。然后,使用encoder-decoder的模型把中间变现形式转换成目标发音人的声学特征。最后,使用声码器合成音频。本文把VC和AC两个任务同时进行,提出了可以转换音色和口音的many-to-many 的声音转化器。
2 详细的系统设计
本文的系统如图1所示,主要分为三步骤:ASR for BN feature extracting, VC model training和conversion。
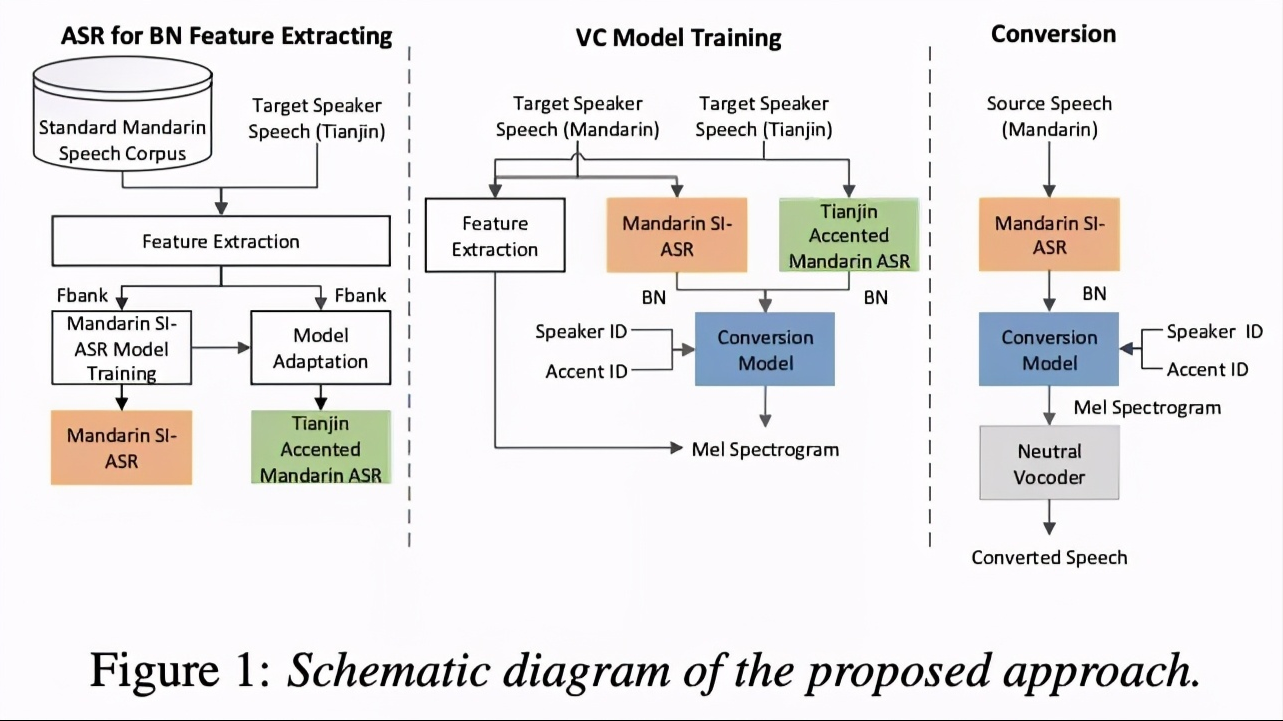
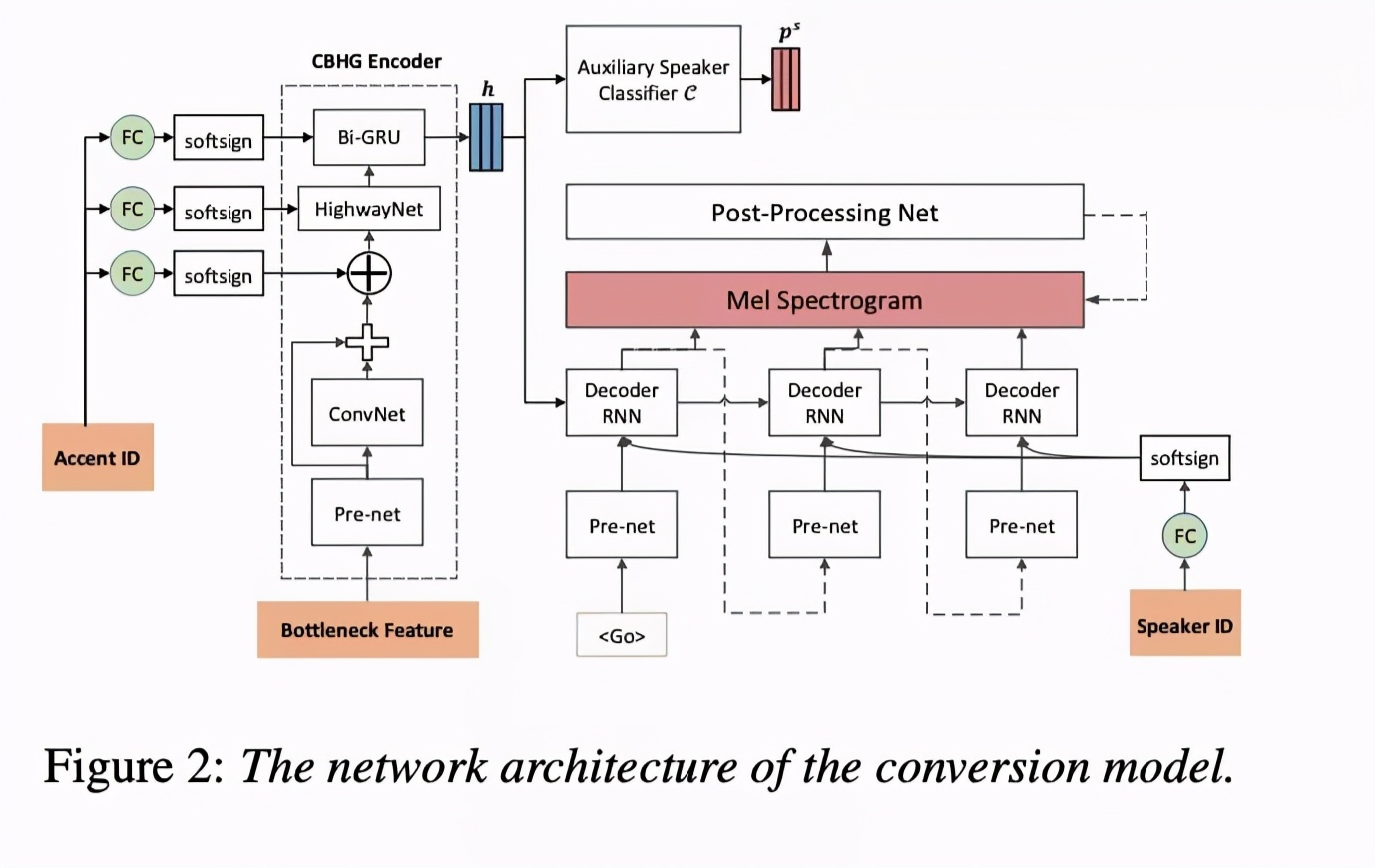
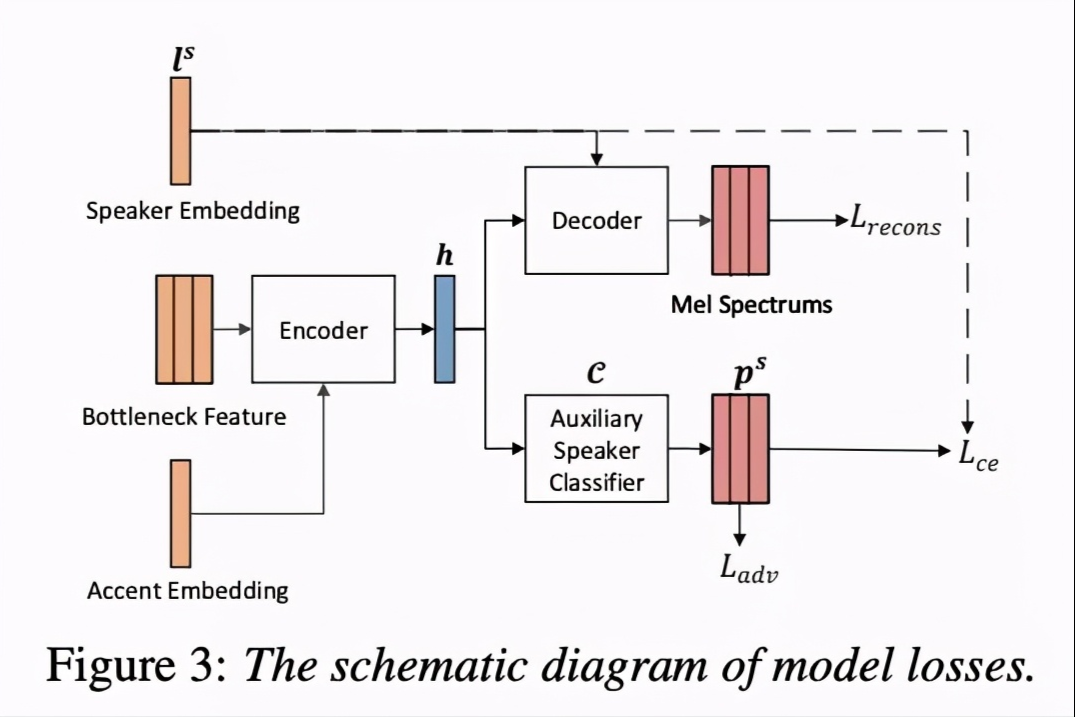
第一个步骤是训练ASR模型,该模型用来获取BN特征,该特征与speaker 无关。第二步骤是使用训练好的ASR模型获取的BN特征训练VC模型。本文使用tacotron模型,但去掉了attention模块。为了使模型支持many-to-many,该模型添加了spk-id和accent-id用来控制音色和口音,具体结构如图2。为了解除speaker和语言特征的绑定,本文添加了auxiliary speaker classifier 模块,该模块常使用adversarial training strategy(ADV)策略。训练该模型主要的loss如图3表示。第三步,是使用训练的ASR和VC模型进行声音转换。
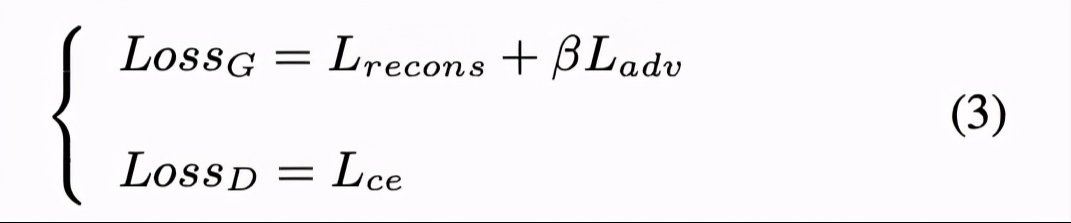
3 实验结果
本文的实验先验证VC模型的每个模块的影响力,然后验证合成音频的质量。
本文把系统分为BL,P1,P2。其中BL是图2结构但没有独立的口音ASR和ADV,P1有独立的口音ASR但没有ADV模块,P2全部具备。图4主要对比P1,P2主要区别的ADV的影响力,由结果可知,采用ADV的句子聚集越紧密,说明语言特征与说话者解绑越好。
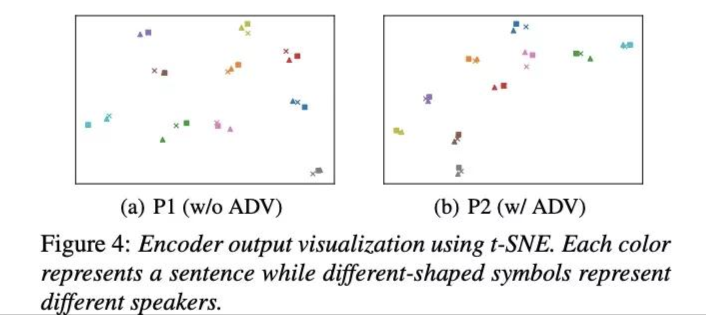
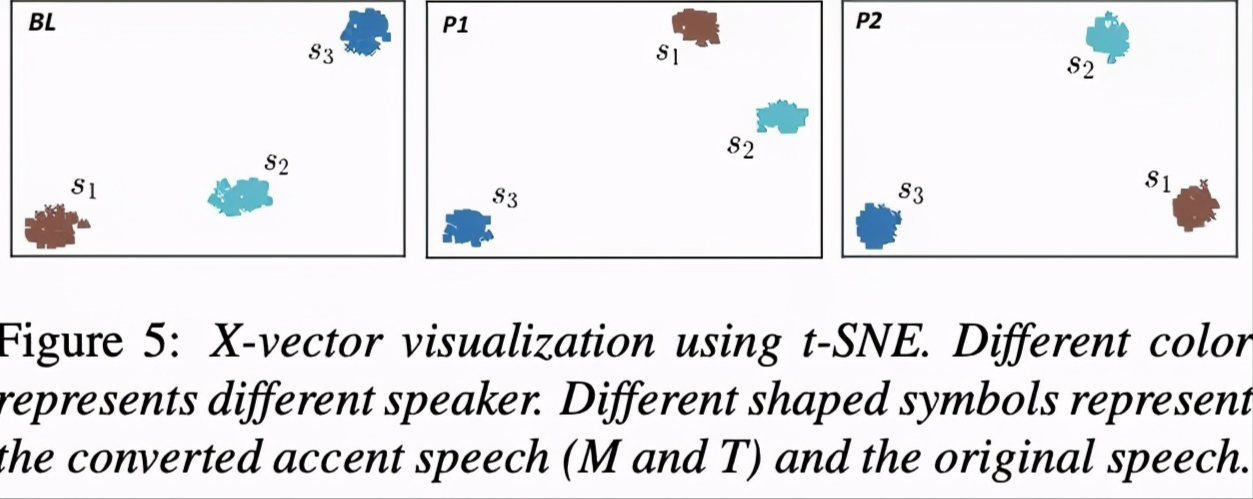
图5验证说话者的相似性,由结果可知,每个spk id合成的语句聚集在一起,说明spk-id学习的很好。
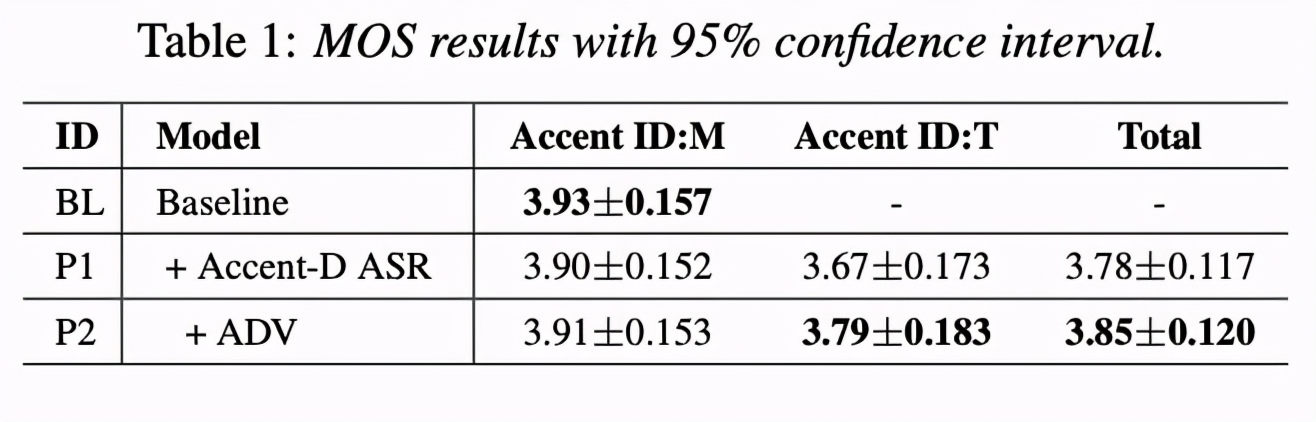
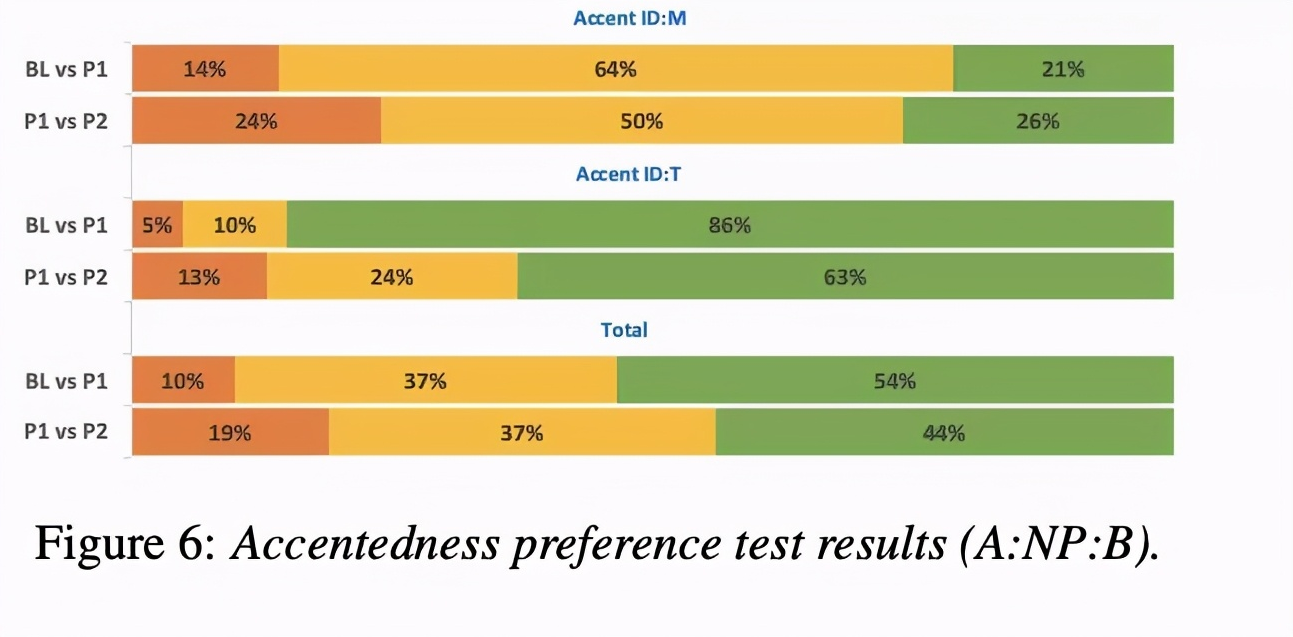
最后比较了合成的音质,由table 1可知,因为BL无法合成口音因此只能测试普通话的MOS。结果显示添加ADV使普通话的MOS稍微降低,但可以合成带口音的语句。同时图6的AB test显示,P2在带口音的具有明显优势。
4 总结
本文主要做many-to-many的VC,同时也进行accent的迁移,比较有趣,给的demo还算不错。(目前也会只正在挂着实验,主要做cross-lingual,其实道理一样)