声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
One Model, Many Languages: Meta-learning for Multilingual Text-to-Speech
该篇文章是查尔斯大学发表,主要工作是做multilingual TTS。该模型使用monolingual的训练语料来训练多语言模型,本文更新时间为2020.08.03,具体的文章链接http://yqli.tech/pdf/tts_paper/2020%20One%20Model%20Many%20Languages%20%20Meta%20learning%20for%20Multilingual%20Text%20to%20Speech.pdf
1 研究背景
当前端到端的语音合成可以合成较高质量的语音,对TTS的研究方向也由多数据高质量单语言转到低质量多语言的研究。现在,很多机器学习的方法被应用到多语言的模型训练,比如:迁移学习(transfer learning), 知识共享(knowledge sharing), 声音复制(voice clone),语言转换(code-switch)等等。本文设计了一种多语言的TTS,该系统主要基于在Tacotron2模型。通过试验比较,本文提出的GEN比现有的多语言模型在语音语音合成质量上更优。
2 系统结构
该系统是在tacotron2基础上进行的修改,详细的系统结构如图1。首先,该系统把tacotron2的encoder部分BLSTM去掉,全部使用卷积层conv,而且每种语言拥有单独的encoder部分。其次,该系统添加parameter generator部分,把音素相应的语言类型信息进行处理然后拼接到encoder的每一层。最后,encoder的输出输入到decoder和speaker classifer部分。(系统整体很简单,至于parameter generator 需要多层FC与encoder 的每一层进行对应,只是感觉这样很复杂。另外DAT 应用也很流行,最近研究DAT这篇文章,该文章35页,需要慢慢消化整理,等后续分享)
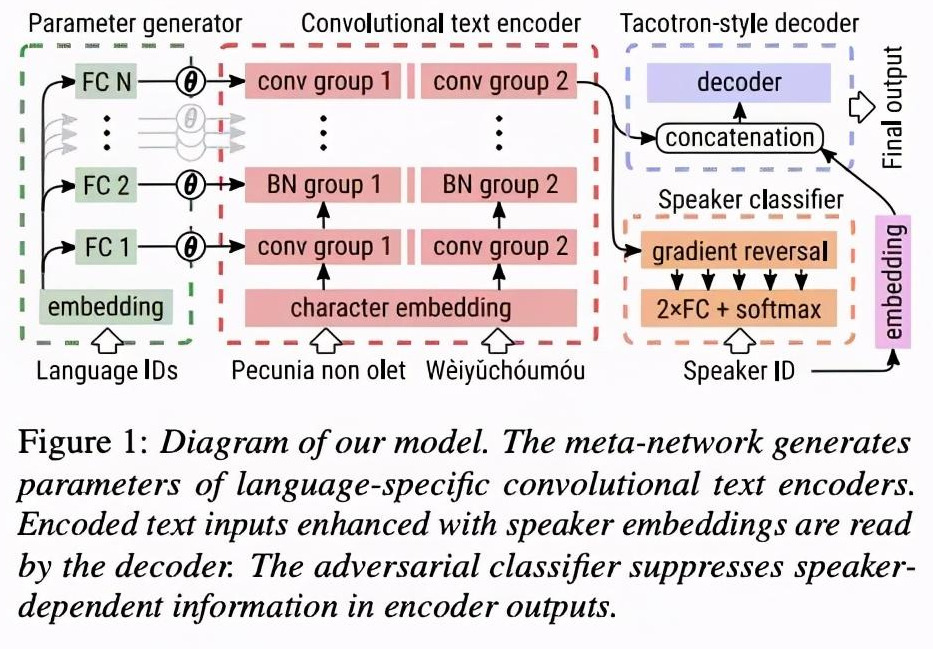
3 实验结果
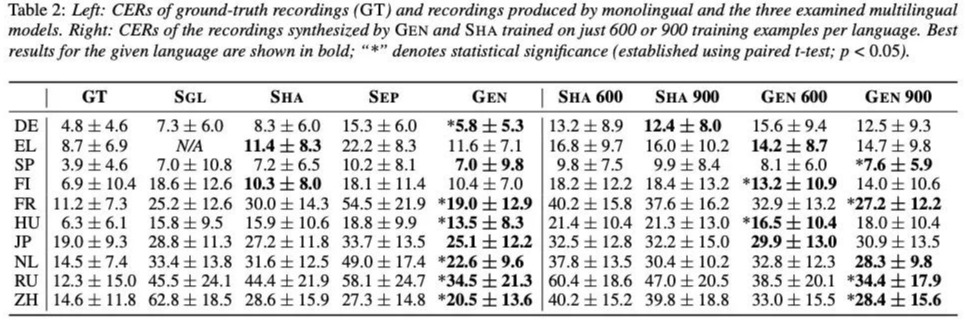
本文对比的系统主要有三类:单语言系统(tacotron2 SGL),encoder 共享系统(SHA), encoder分离系统(SEP)。本文的系统被命名为GEN。首先,对比集中系统合成的音质,该对比先使用各类系统合成音频,然后使用ASR对合成的语音进行识别,测CER。从Table 2 的左侧部分可知,本文的GEN在大部分语言效果相对好一些(加粗部分),Table2右侧部分是进行少数据的压测,由结果可知,GEN的效果比SHA较好。
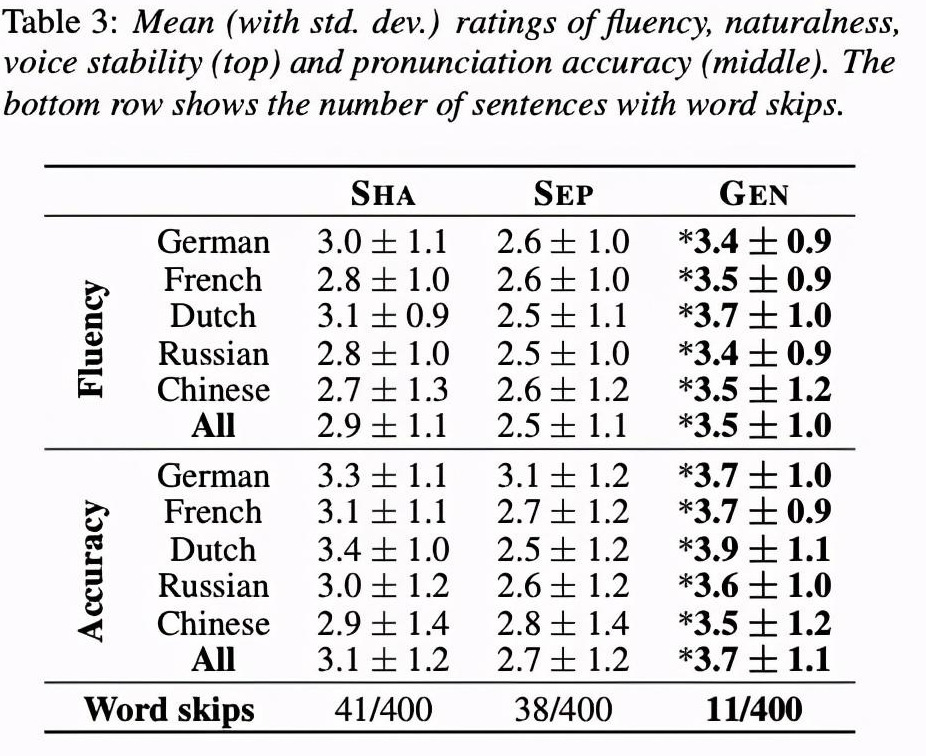
其次对比合成质量MOS和漏字情况,从Table 3和图4可知,Gen效果最好。

4 总结
本文提出了处理多语言的TTS模型,个人感觉主要还是在encoder部分和language部分,不过使用fc栈式跟encoder每一层进行1对1关系有点繁琐,不过好坏还需要自己试验一下。