来源:so.csdn.net
发布时间:Nov 29, 2020, 12:57:40 AM
原地址:https://blog.csdn.net/qq_40584593/article/details/110311540
api注册
首先进度百度智能云,之后在里面注册一个语音识别api,获得密钥进行拼接使用
百度智能云
2.创建应用
3.里面内容可以随便填
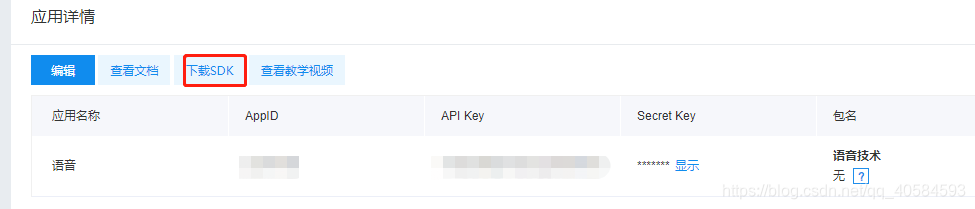
4.获得使用的密钥
5.刚开始还不能够直接使用,还需要获得免费次数,直接领取就可以

短音频识别
1.官方例子
2.不需要下载,直接看说明
3.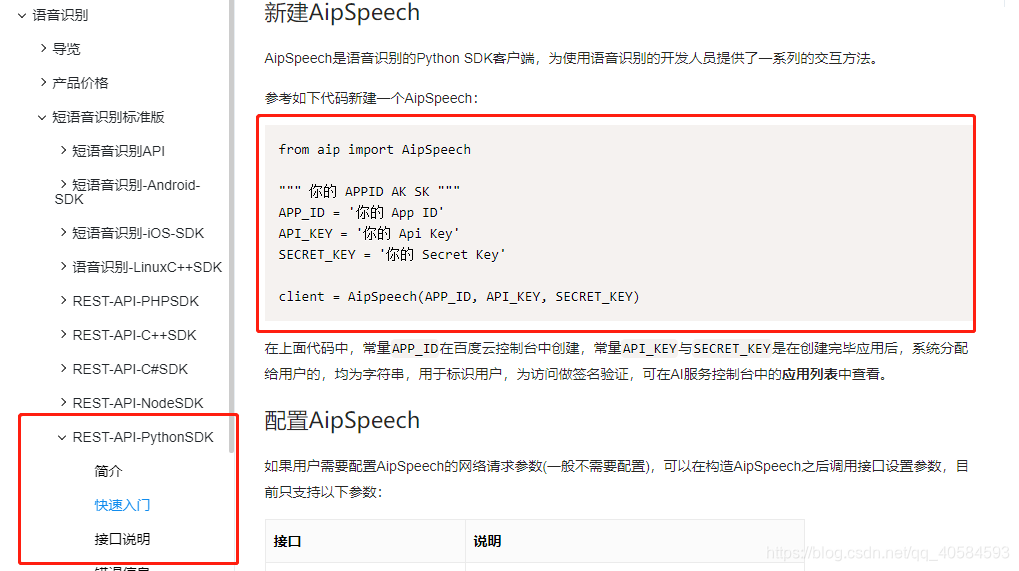
4.其中aip包可以通过
pip install baidu-aip

5.短时间举例子
语音参数 必须符合16k或8K采样率、16bit采样位数、单声道
语音格式 PCM、WAV、AMR
from aip import AipSpeech
def baidu_Speech_To_Text(filePath): # 百度语音识别
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
aipSpeech = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 初始化AipSpeech对象
# 读取文件
with open(filePath, 'rb') as fp:
audioPcm = fp.read()
json = aipSpeech.asr(audioPcm, 'wav', 16000, {
'lan': 'zh', })
print(json)
if 'success' in json['err_msg']:
context = json['result'][0]
print('成功,返回结果为:', context)
else:
context = '=====识别失败====='
print('识别失败!')
return context
# oldPath='./audio/韩红 - 家乡.mp3'
oldPath = './audio/16k.wav'
# oldPath='temp-1.wav'
baidu_Speech_To_Text(oldPath)
资源地址:
https://download.csdn.net/download/qq_40584593/13203211
结果返回:
{‘corpus_no’: ‘6900431893696192867’, ‘err_msg’: ‘success.’, ‘err_no’: 0, ‘result’: [‘北京科技馆。’], ‘sn’: ‘548295614521606631998’}
成功,返回结果为: 北京科技馆。
长音频识别
# -*-encoding:utf-8-*-
""" # function/功能 : # @File : x2.py # @Time : 2020/11/29 10:18 # @Author : kf # @Software: PyCharm """
import os
from aip import AipSpeech
from pydub import AudioSegment
from pydub.utils import mediainfo
def sound_cut(file_name):
if os.path.exists('识别结果.txt'):
os.remove(r'识别结果.txt')
song = mediainfo(file_name)
song_length = str(int(float(song['duration']))) # 读取文件时长
song_size = str(round(float(int(song['size']) / 1024 / 1024), 2)) + 'M' # 读取文件大小保留两位小数round(变量,2)
song_filename = song['filename'] # 读取文件地址
song_format_name = song['format_name'] # 读取文件格式
print('\t长度', song_length, '\t文件大小', song_size, '\t文件路径', song_filename, '\t文件格式', song_format_name)
cut_song_num = int(int(song_length) / 59) + 1 # 每段59s,计算切割段数
print('切割次数', cut_song_num)
sound = AudioSegment.from_mp3(file_name)
# 单位:ms
stat_time = 0
end_time = 59
for i in range(cut_song_num):
if i == cut_song_num - 1: # 判断如果是最后一次截断
cut_song = sound[stat_time * 1000:] # 截取到最后的时间
end_time = int(song_length)
else:
cut_song = sound[stat_time * 1000:end_time * 1000]
save_name = r"temp-" + str(i + 1) + '.mp3' # 设置文件保存名称
cut_song.export(save_name, format="mp3") # 进行切割
save_name_pcm = r"temp-" + str(i + 1) + '.wav' # 设置文件保存名称
mp3_version = AudioSegment.from_mp3(save_name) # 可以根据文件不太类型导入不同from方法
mono = mp3_version.set_frame_rate(16000).set_channels(1) # 设置声道和采样率
mono.export(save_name_pcm, format='wav', codec='pcm_s16le') # codec此参数本意是设定16bits pcm编码器, 但发现此参数可以省略
context = baidu_Speech_To_Text(save_name_pcm)
with open(r'识别结果.txt', 'a', encoding='utf-8') as f:
f.write(context)
os.remove(save_name) # 删除mp3文件
os.remove(save_name_pcm) # 删除mp3文件
print(save_name, 'end_time=', stat_time, 'end_time=', end_time)
# 切割完加入下一段的参数
stat_time += 59
end_time += 59
def baidu_Speech_To_Text(filePath): # 百度语音识别
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
aipSpeech = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 初始化AipSpeech对象
# 读取文件
with open(filePath, 'rb') as fp:
audioPcm = fp.read()
json = aipSpeech.asr(audioPcm, 'pcm', 16000, {
'lan': 'zh', })
print(json['err_msg'])
if 'success' in json['err_msg']:
context = json['result'][0]
print('成功,返回结果为:', context)
else:
context = '=====识别失败====='
print('识别失败!')
return context
file_name = r'./audio/世间最美的坟墓.mp3'
sound_cut(file_name)
示例文件:
https://download.csdn.net/download/qq_40584593/13203219
结果:
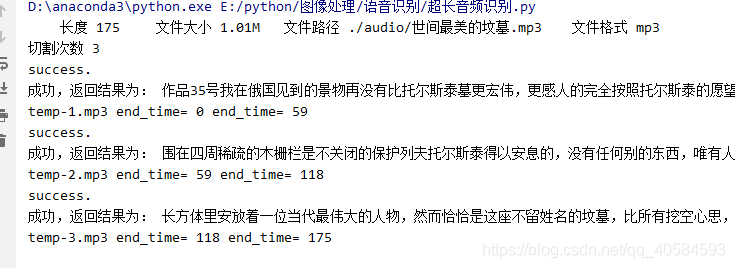
音频格式转换
# -*-encoding:utf-8-*-
""" # function/功能 : # @File : mp3变成wav.py # @Time : 2020/11/29 10:09 # @Author : kf # @Software: PyCharm """
import numpy as np
from pydub import AudioSegment
def mp32wav(from_path, to_path, frame_rate=16000):
# from_path: 目标音频文件路径
# to_path: 转码后文件路径
# frame_rate: 默认16kHz,可以frame_rate=8000,既8kHz
mp3_version = AudioSegment.from_mp3(from_path) # 可以根据文件不太类型导入不同from方法
# ogg_version = AudioSegment.from_ogg("never_gonna_give_you_up.ogg")
# flv_version = AudioSegment.from_flv("never_gonna_give_you_up.flv")
mono = mp3_version.set_frame_rate(frame_rate).set_channels(1) # 设置声道和采样率
mono.export(to_path, format='wav', codec='pcm_s16le') # codec此参数本意是设定16bits pcm编码器, 但发现此参数可以省略
def wav2pcm(wavfile, pcmfile, data_type=np.int16):
f = open(wavfile, "rb")
f.seek(0)
f.read(44)
data = np.fromfile(f, dtype=data_type)
data.tofile(pcmfile)
def trans_mp3_to_wav(filepath, filepath2):
song = AudioSegment.from_mp3(filepath)
song.export(filepath2, format="wav")
# oldPath='./audio/韩红 - 家乡.mp3'
# newPath="./audio/韩红 - 家乡.wav"
# wavfile="./audio/韩红 - 家乡.wav"
# pcmfile="./audio/韩红 - 家乡.pcm"
wavfile = "./audio/16k.wav"
pcmfile = "./audio/16k.pcm"
# mp32wav(oldPath,newPath)
wav2pcm(wavfile, pcmfile)
项目地址
https://github.com/Kuangfa/audioRecognition/tree/master
参考网页
- https://blog.csdn.net/Lynn_coder/article/details/79436579
- https://farm.readdinner.com/post/shi-yong-dui-yin-pin-jin-xing-zhuan-ma-man-zu-bai-du-yu-yan-he-teng-xun-chang-yu-yan-shi-bie-yao-qiu
- https://blog.csdn.net/a506681571/article/details/85201279
- http://www.xikrs.com/b(1)/lsb5b.htm
- https://blog.csdn.net/li_ji_an/article/details/102841611