《噪声环境下的语音关键词检索》阅读笔记
摘要:为了实现免手持语音识别的体验,语音识别系统需要持续不断地监听特定唤醒词语来开启语音识别任务,这个过程通常被定义为关键词检索(KDW)或者关键词识别(KWS)。在现实生活中,噪声干扰不可避免,噪声鲁棒性对关键词识别任务至关重要,因此我们为提高关键词的鲁棒性做了三方面的尝试。首先,将语音增强系统和关键词检测系统连接起来构成更复杂的系统,整个系统采用联合训练的方法。第二,提出了一种新的卷积循环神经网络。最后,为了进一步提升系统的性能,设计了特征转换模块。本文采用基于联合训练框架的CNN-MelCRN32关键词检测系统在测试集上的准确率为93.17%,与带噪训练的(基于multi-condition训练方法)基线系统,相比相对提升64.2%,显著的提高了关键词检测系统的噪声鲁棒性。
总结与展望
关键词检测系统在生活中中越来越重要,但在不同场景下,噪声以及无关人声的干扰,人们对于关键词检索系统要求的鲁棒性越来越高。除此之外,关键词在尽量保持“时刻监听”的状态,会给智能设备带来巨大的能量损耗,本文模型在设计时,以降低模型参数量和计算复杂度为原则。
虽然本文提出的方法在噪声鲁棒性能和计算资源占用上有很显著的优势,但鲁棒性关键词检测系统还有很大的优化和改进空间。
1.本文实用CNN模型,本身识别性能一般,18年提出基于残差网络的识别器有更好的识别性能并且计算资源占用更小。后续可更换识别器。
2.本文仅使用了单个增强特征,后续会尝试多种特征组合。
3.在增强实验中,使用的损失函数为均方误差。然而MSE会弱化低能量部分的重要性,而散类度的损失函数使用比值的形式避免了这个问题。
引言:
关键词检索系统的研究方法大致分为三类。基于模板匹配的方法:具有模型尺寸小,计算量少的优点但准确率比较低;基于关键字-补白模型的方法:会为关键字和非关键字分别建立模型,使用通过维特比解码算法来判断输入的音频中是否出现了关键字。这种方法需要大量对关键字和非关键字的训练;基于大词表连续语音识别的方法:源于语音识别任务,但也有不同之处,关键词检测系统的目标为孤立词。
深度学习的兴起,也深入到关键词检索领域,形成了一种端到端的主流模式,基于端到端的关键词检索系统包含三个部分:特征提取模块,神经网络模块和输出后验得分的计算模块。目前,评价关键词检测系统的性能指标主要有,准确率,ROC曲线等。(ROC曲线综合考虑了系统的错误拒绝率和错误接受率,曲线越偏向零点代表性能越好。)
关键词检测系统
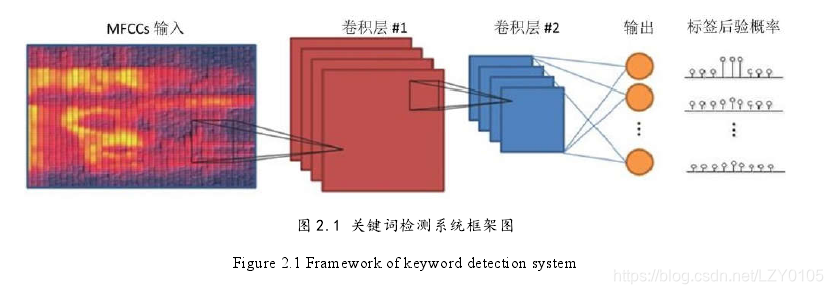
本文的关机词检测系统参考tensorflow基线系统进行设计,基于端到端模式并丢弃了语言模型。主要结构包括特征提取模块,基于卷积神经网络的声学模型,后验概率处理模块。特征提取模块进行声音活动检测(VAD)并对每一帧音频计算特征向量,之后将预设帧数的级别特征向量按帧堆叠成特征谱图,送入卷积神经网络中。我们训练CNN声学模型来预测每一个标签的后验概率,这些标签代表一个关键词或者说是关键词的一部分。后验概率处理模块会将CNN输出进行平滑,对每一个标签计算一个平滑窗内的置信度,置信度分数最高的即为预测的关键词或者非关键词。
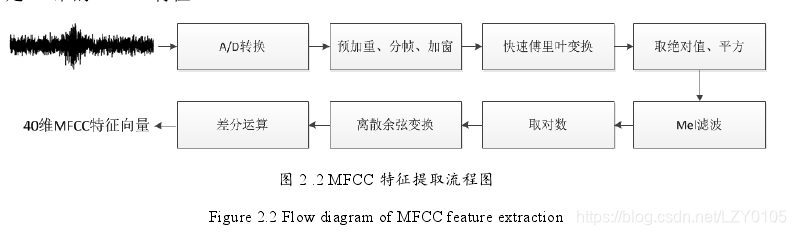
1.特征提取:将语音信号的模拟信号转变为数字信号,之后对数字信号进行特征提取。本文采用的特征是Fbank特征和MFCC特征。MFCC特征考虑了人类听觉感知只聚焦在某些特定频率的特性,提取过程如下:对音频信号进行预加重、分帧、加窗处理。预加重操作的目的是提高语音中高频的部分,使得信号在低频到高频的整个频谱变得平坦。分帧时为避免丢失信息,采取重叠分段的方法,一帧的时长为帧长,相邻两帧的起始位置时间差为帧移。加窗是将语音信号与窗函数相乘,方便之后做傅里叶变换。预处理之后,对语音信号作短时傅里叶变换得到频谱,之后对频谱取模平方后可以得到信号功率谱。Mel滤波器组操作得到mel倒谱特征。
2.基于卷积神经网络的声学模型
早期基于HMM模型的声学模型是关键词检测系统的主流。但现在基于神经网络的端到端声学模型逐渐取代了HMM的声学模型,这类模型不需要解码部分,实现较为容易,并且模型的输出为每一个标签的后验概率,经过后验处理模块平滑处理后给出每一个标签的置信度得分。相比于基于DNN的声学模型,CNN能更好学习时频关系,并且需要更少的计算资源。
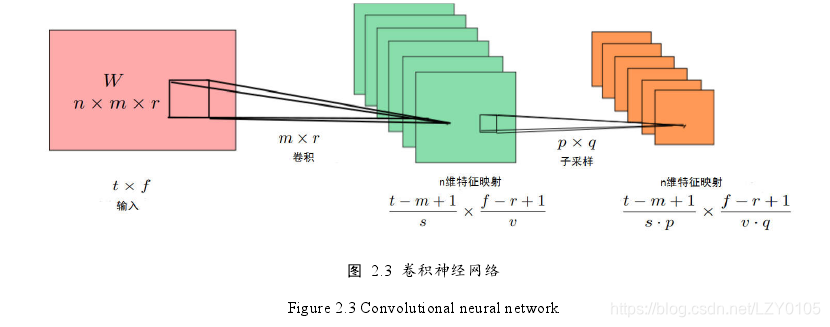
图中hi一层卷积层和池化层。网络的输入信号为tf的特征向量,t为时间维度,f代表频率维度。卷积核大小为mr(m<=t,t<=f)s:时间轴长度,v:频率轴长度。经过卷积得到n个特征映射,然后进行降采样,池化窗为p*q,但在本文中没有进行池化。最后一层为softmax层,其输出的每一个结点对应一个关键词标签和非关键词的标签,输出为某关键词和非关键词的后验概率估计值。
3.后验概率处理
后验概率值是每一帧音频对应标签的后验概率。需要在一个固定时长的平滑窗内对后验概率值进行平滑。平滑公式为:

随后将一定帧数的后验概率组合起来,计算出大小为Wmax滑动窗内的后验概率值及置信度分数。置信度计算公式为:

若为单个关键字,当置信度超过预先设定的阈值时,则包含关键词。若为多个关键词和非关键词分类,选取最大的置信度对应的标签,模型认为该音频包含关键词或非关键词。
语音关键词检测基线系统
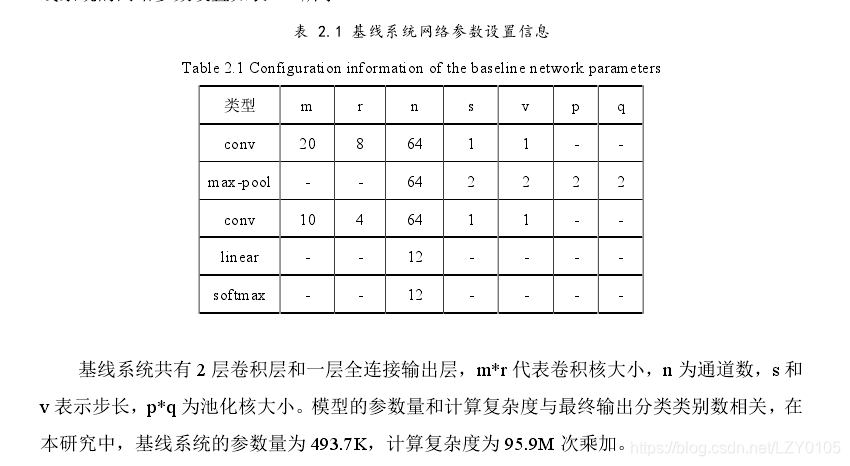
基线系统有两层卷积层和一层全连接输出层。
基线系统的性能评估
本文基线系统的性能评估指标使用准确率、ROC曲线,AUC,EER。ROC曲线的横轴是(FPR即我们说一些发音近似唤醒词但不是唤醒词的语句时,它能够不被唤醒,假正确率),纵轴为(TPR即为说出关键词能正确唤醒设备),曲线越偏向左上角性能越好。若一条曲线被另一条曲线包住,则后者识别器性能更优,若曲线发生交叉,无法判断时采用AUC(ROC曲线下的面积,取值范围[0,1])
基于深度学习的有监督的语音增强方法
这个部分在这里不做标记,想了解的可以参考汪德亮老师的综述,详细的介绍了单通道语音增强。
模型训练策略
我们所尝试的训练策略,第一种是分别训练好语音增强模型和关键词检测模型,即使带噪语音先经过增强模型进行降噪,之后将纯净语音送入关键词检测模式进行识别。但这种模式有缺陷,语音增强的训练目标是以最大化信噪比为准则,在这种准则下语音的可懂度和语音真实性无法得到保证,会导致语音失真,使得关键词检测模型无法准确识别。第二种训练策略是使用经过增强模型降噪之后的训练特征和测试关键词检测模型。但这种方法太过于依赖语音增强模型的性能。第三种就是联合训练,将两个模型合起来生成更大的模型,通过反向传播算法联合训练两个模型,语音关键词检测模型中的语言学和其他有用的信息可以传送给语音增强模型,使两个模型彼此优化。
基于Joint-BiLSTM的鲁棒性关键词检测系统
系统架构:
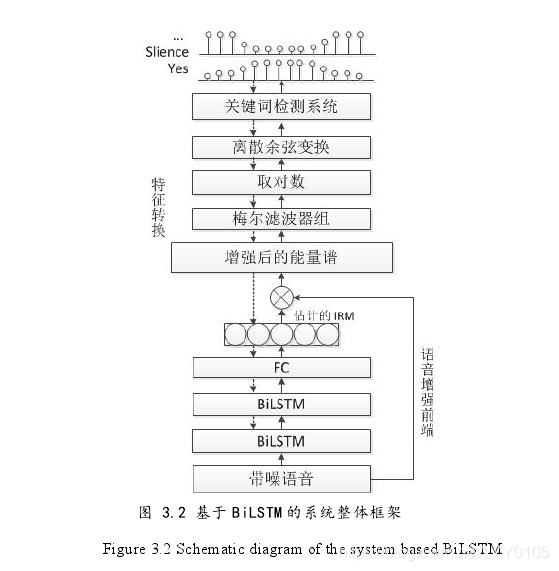
关键词检测系统的输入特征为MFCC,输出某一个类别的后验概率,通过计算平滑窗内的置信度得分来推断关键词类别。识别模型使用的网络为CNN模型,增强模型为2层BiLSTM,每层384结点,训练CNN的损失函数是交叉熵,训练BiLSTM模型的损失函数为均方误差,使用Adam优化器。
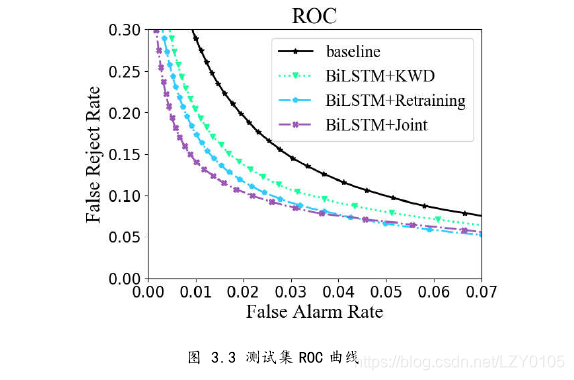
实验结果分析
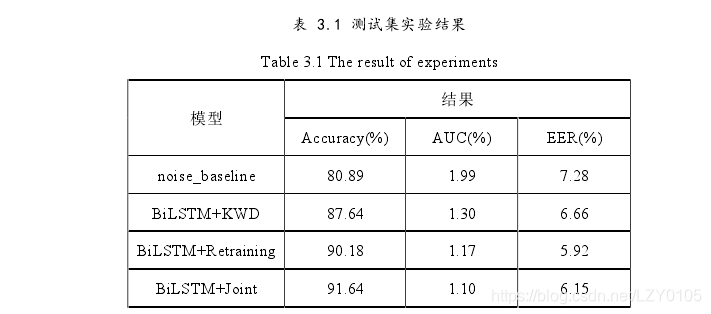
可以看出,我们的训练模型显著提升了关键词检测系统的识别性能,提高了关键词检测模型的背景噪声鲁棒能力。
低资源占用的卷积循环神经网络
本文设计了一种新颖的CRN结构,在CRN结构中组合了CNN编码器和长短时记忆层。除此之外还研究了特征转换模块,并对比了能量域特征和梅尔域特征。
CRN结构,采用CNN进行编码解码,解码器之后是一层sigmoid输出层。编码器是堆叠了几层卷积层(两种特征域的系统结构卷积层数不同),解码器结构和编码器相对应,保证了系统的输出跟输入有相同的维度。在卷积编码结构中无法利用上下文信息,而为了追踪目标说话人,利用上下文信息非常重要,所以引入LSTM。在编码器和解码器中间加入一层双向LSTM。
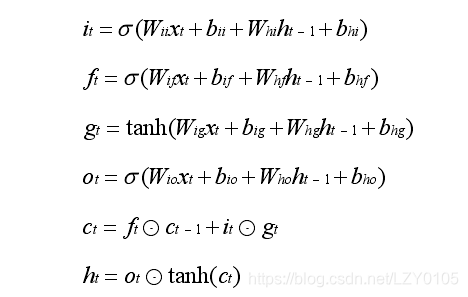

引入了两种增强特征,能量谱和梅尔谱,分别对两种特征设计了基于CRN的网络。对比本实验中全部模型,从模型类别、特征域、音标数量敏感、训练策略以及噪声泛化五个方面进行分析。结果表明,本文提出的低资源占用的CRN在噪声匹配和不匹配的情况下,与基于BiLSTM模型相比,有着更好的性能,同时需要少量的计算资源。不仅如此,提出的基于梅尔域的增强特征在关键词检测任务上性能表现优于能量谱特征,并且对关键词的音标数量不敏感。