声明:工作以来主要从事TTS工作,工程算法都有涉及,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 http://yqli.tech/page/tts_paper.html TTS 开源数据 http://yqli.tech/page/data.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
目录
2.3 效率的提升策略之多采样(multi-sampling)
1 背景
TTS的工作主要是把文本信息转成音频信息,其大致流程分为前端处理和后端处理两个部分。前端的工作主要是语言领域的处理,主要包括分句、文本正则、分词、韵律预测、拼音预测(g2p),多音字等等。后端的主要工作是把前端预测的语言特征转成音频的时域波形,大体包括声学模型和声码器,其中声学模型是把语言特征转成音频的声学特征,声码器的主要功能是把声学特征转成可播放的语音波形。声码器的好坏直接决定了音频的音质高低,尤其是近几年来基于神经网络声码器的出现,使语音合成的质量提高一个档次。目前,声码器大致可以分为基于相位重构的声码器和基于神经网络的声码器。基于相位重构的声码器主要因为TTS使用的声学特征(mel特征等等)已经损失相位特征,因此使用算法来推算相位特征,并重构语音波形。基于神经网络的声码器则是直接把声学特征和语音波形做mapping,因此合成的音质更高。目前,比较流行的神经网络声码器主要包括wavenet、wavernn、melgan、waveglow、fastspeech和lpcnet等等。其中,lpcent兼具复杂度低,合成音质高等优点,因此受到学术界和工业界的关注。本文主要关注lpcnet声码器的发展动向,对具有代表性的几篇文章进行总结。(本文稍长,还请读者耐心阅读,如有错误,还望指出)
2 研究情况
到目前为止,研究lpcnet的文章很多,主要研究两个维度:提高音质和降低复杂度。其采用的策略大致包括LP-MDN,gmm采样,multi-sampling多采样,multiband等等(其中lpcnet系统自带的稀疏化等策略,我们不再关注讲解)。本文根据采取的优化策略选取以下6篇具有代表性的文章:
1)LPCNet: Improving Neural Speech Synthesis Through Linear Prediction
2)Improving LPCNet-based Text-to-Speech with Linear Prediction-structured Mixture Density Network
3)Gaussian Lpcnet for Multisample Speech Synthesis
4)Bunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems
5)FeatherWave: An efficient high-fidelity neural vocoder with multi-band linear prediction
6) An Efficient Subband Linear Prediction for LPCNet-based Neural Synthesis
接下来的主要组织结构:2.1小节回顾原始的Lpcnet系统,主要文章1;2.2小节为音质的提高策略,主要包括文章2(这个不能严格说那些策略只提升性能或者质量,后边加速策略multiband不仅可以提高性能,音质也提高不少);2.3 效率的提升策略之多采样(multi-sampling),主要文章3和文章4;2.4 效率的提升策略之多频带(multiband),主要文章5和文章6。
2.1 Lpcnet
LPCNet: Improving Neural Speech Synthesis Through Linear Prediction,该文章主要提出了神经网络声码器Lpcnet。该声码器把source-filter部分的source使用神经网络来预测,而filter部分则使用DSP的方法进行计算,具体如下的公式。其中每个采样点x是由filter部分的p和激励e来计算,而激励e使用神经网络来预测,p则直接根据DSP方法计算出来。
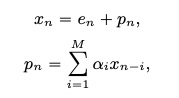
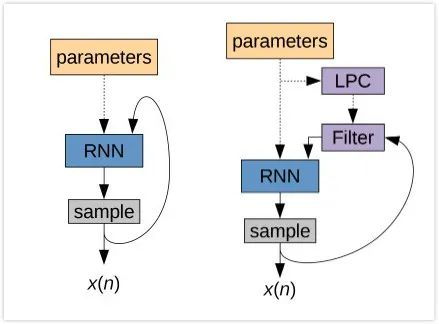
lpcnet声码器其原理和wavernn的区别如下图所示:左边为wavernn的示意图,该网络直接对采样点进行预测,整个流程为自回归模型。右边为lpcnet的示意图,其神经网络只对source的激励e进行预测,而filter的部分直接进行计算获取。该文章的作者回答这样的做的原因,是他认为使用一个神经网络不能同时很好的推算source和filter的两部分信息。
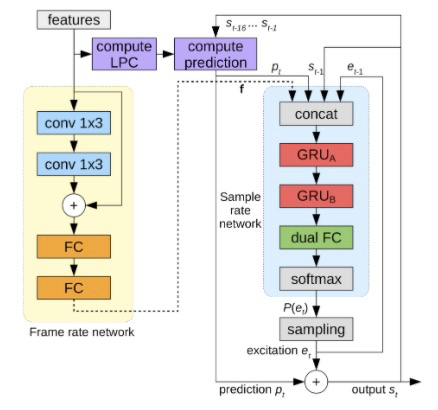
接下来看一下Lpcnet的详细系统架构,如下图所示。整个系统由帧级别的frame rate network(黄色部分)和采样点级别的sampling rate network(浅蓝色部分)。frame rate network每一帧计算一次,其中使用了2层1*3的一维卷积,因此该网络的感受视野为5帧。sampling rate network是每一帧计算160次(如使用16khz的音频,10ms帧移),该部分为autoregressive模型,每一个激励e的推测都需要前一个推测e作为条件。
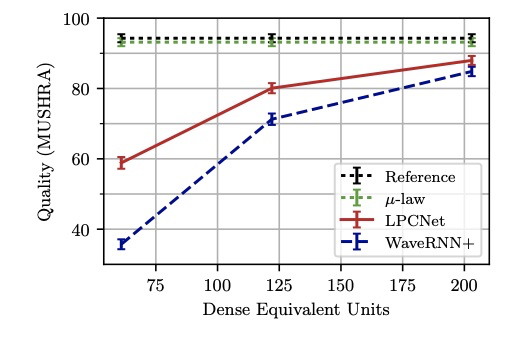
接下来看一下声码器lpcnet的实验结果。首先,通过计算lpcnet的复杂度为2.8GFLOPS,而其它典型的声码器wavenet为16GFLOPS,wavernn为10GFLOPS,SampleRNN为50GFLOPS,由此可以看出lpcnet的复杂度非常低。另外,合成音质方面如下图所示,ref线为原始音频,绿色线为u-law转换,该转换造成部分音质降低,红色线为lpcnet,蓝色线为wavernn。由图可知lpcnet在相同的复杂度情况下,合成的音质是优于wavernn。
2.2 音质的提高
该部分主要讲一下Improving LPCNet-based Text-to-Speech with Linear Prediction-structured Mixture Density Network这篇文章。这篇文章主要在保持Lpcnet较低复杂度的优点前提下,提出LP-MDN,提高了语音合成质量。本文提到Lpcnet模型并没有完全利用语音合成的机制,而且激励参数使用u-law量化造成不稳定现象。针对以上问题,本文做出以下贡献 1)提出基于LP-MDN的声码器ilpcnet,该声码器可以充分利用lp和激励之间的关系,替换原来的激励u-law离散分布,使合成音质提高。2)提出训练和生成的策略,比如stft loss等等。考虑到采样点和激励之间的分布关系,本文提出LP-MDN(mdn和gmm之间区别:mdn的均值、方差等参数是网络产生,gmm的均值、方差等参数是估计出来的),该模型假设speech和激励之间的分布关系如下图所示,因此可以使用神经网络进行w,u,s的预测。

本文把LD-MDN融合到Lpcnet提出了ilpcnet,具体的结构如下图所示。其中与原始的lpcent不同点为 1)upsampling network最后一层由fc替换成conv;2)waveform generation network的grua的输入只有上一个采样点和frame feature;3)最后使用LP-MDN进行采样点生成。
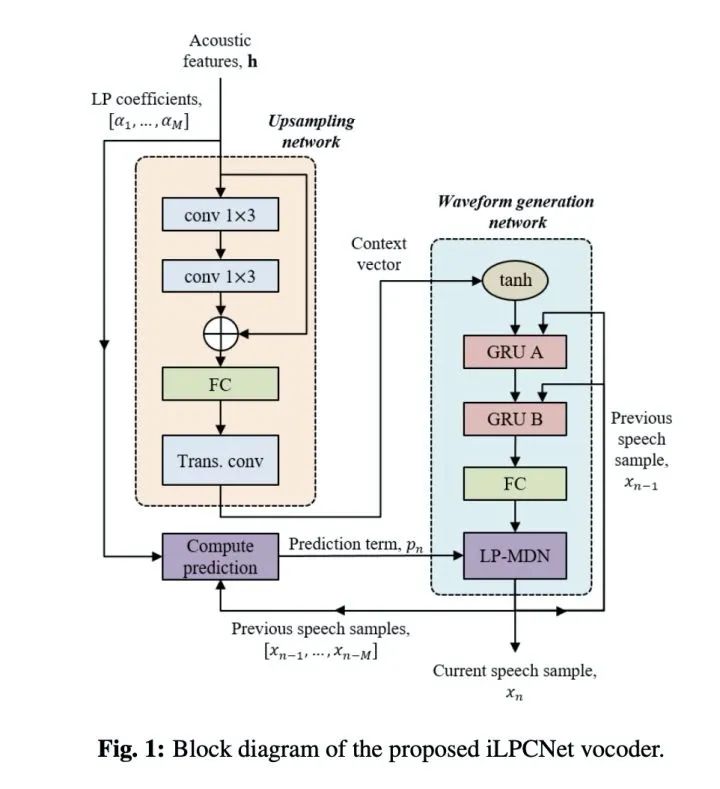
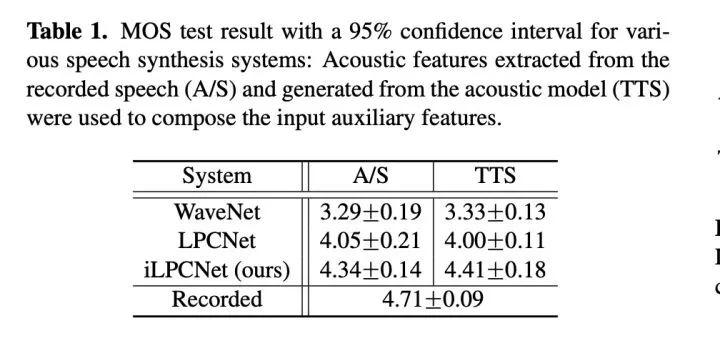
现在看一下实验结果。本文实验很简单,只对比合成质量MOS和ABtest。table 1显示本文提出的ilpcnet比原始的lpcnet合成音质的MOS得分提高0.4(这就厉害了,而且wavenet竟然这么低?仅仅做个参考吧!)。ABtest测试也显示本文提出的方案ilpcnet远远比lpcnet较更受听者喜爱。

小结:lpcnet是DSP和神经网络相结合的声码器,对DSP比较熟的话对该声码器优化具有较优的优势。
2.3 效率的提升策略之多采样(multi-sampling)
部分主要涉及两篇文章:Gaussian Lpcnet for Multisample Speech Synthesis和Bunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems。
原来的lpcnet主要对激励e部分进行预测,而且该部分网络samlping rate network为autoregressive的模型,每次只推理一个值。为了提高推算速度,则提出一次推出多个值。
首先我们先看一下Gaussian Lpcnet,本文章提出了基于Gaussian 采样方法和multisample多点采样的方法,使其在合成质量相当的前提下,合成速度提高了1.5倍(该工作相当不错)。相对于原始Lpcent,本文主要做以下几点的改进:第一,使用Gaussian 采样替代原来的softmax。原来的音频需要进行u-law转换,使用8bit进行采样点表示(造成音质损失),则softmax的维度则为256。本文使用gaussian直接对16bit进行采样,则采样部分由原来lpcnet的dualfc(256)+softmax(256)替换成fc1(128)+fc2(2)。另外文章提到不需要对音频进行加重处理。第二,本文章进行采样时每一步推理两个采样点(两点之间互不影响)。详细结构如图2:左边为原始lpcnet结构,右边为本文的guassian lpcnet的结构。
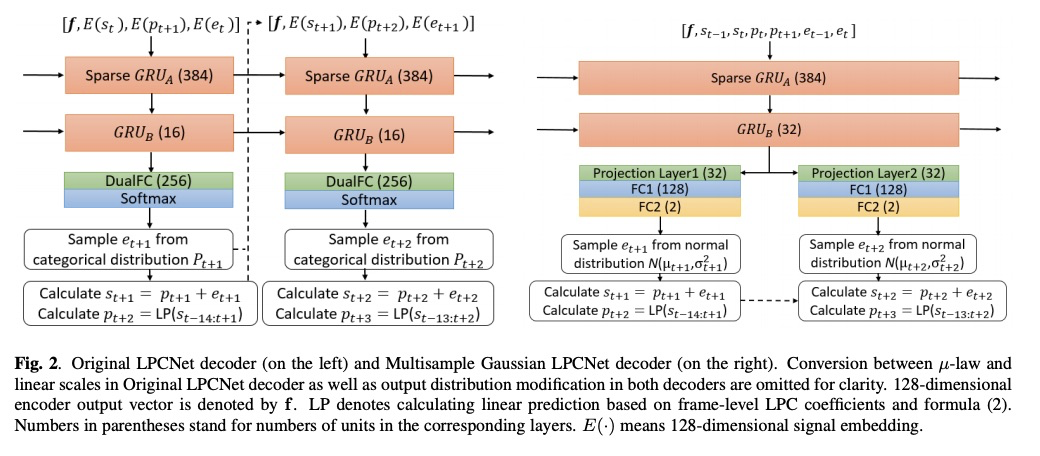
实验结果:table 1主要对比MOS值,其结果证明本文提出的系统合成质量跟原始的LPCNET结果相当。Table 2对比模型的大小和实时率,由结果可知,gaussian lpcnet的参数量更小,其合成实时率更高,其速度比原始的lpcnet快1.5倍。
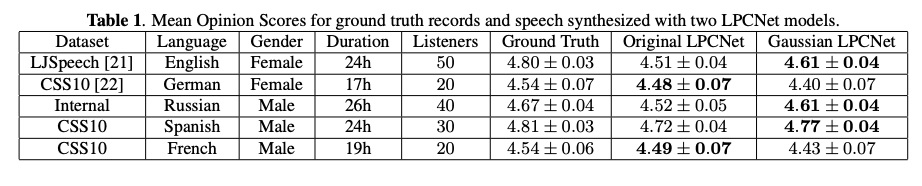

其次,看一下文章bunched lpcnet。该文章为了提高音质,设计如下图的结构,GRUa和GRUb部分都是多点共享,Dual-FC和softmax是每点独享。但每个激励之间并不是独立的,从第二个激励参数e开始,其的输入需要前一个e与gru输出进行拼接,该部分也是一个自回归的模式。而且gruA的输入不再输入一个点的信息,而是输入多个点的信息。该结构通过共享GRU部分,按理说该部分的推理速度正比于bunch sample的大小。
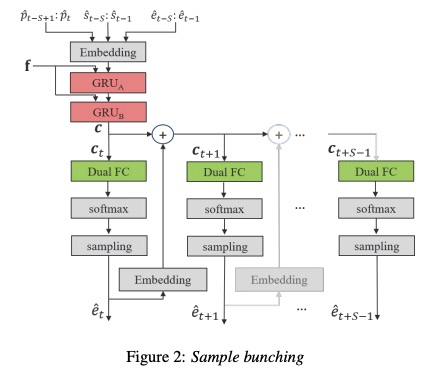
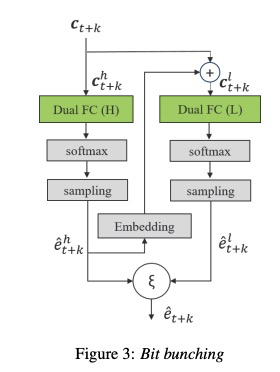
原始的lpcnet系统bit为8位,则softmax为256。为了减小softmax,该部分提出了bit bunching(本篇文章主要使用B=11,分为(7,4),则softmax大小分别为(128,8)),就是用较小的softmax 来表示激励的高和低bit,具体如图3所示。
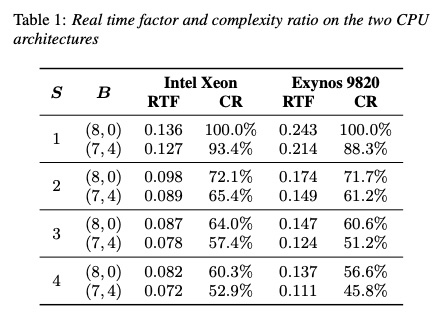
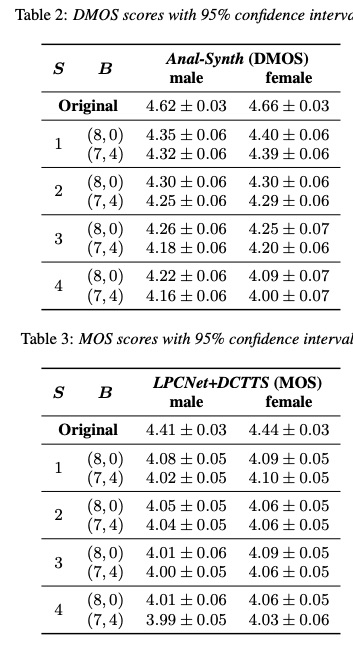
接下来看一下bunched lpcnet实验结果:本实验的 S和B分别代表sample bunching和bit bunching。其中s=1, b=(8,0)为原系统lpcnet,其作为基准。table1对比了RTF(real time factor)和CR(complexity ratio),由结果可知,增大S和改变B,其速度提升很多。尤其S=4,B=(7,4)比S=1,B=(8,0)速度提高了差不多2倍。从Table 2和Table3的mos测试可知,提高S和B会造成MOS下降,在可接受范围内S=2选择较好。
小结:multi-sampling的方法的本质就是解决开销最大的gru层,使其多点共享,剩余的层可以独享。本方法还需要注意各激励之间的关系,使用局部的autoregressive是非常有必要的。另外输入条件p,e,s可以尝试不同的搭配和嵌入维度,由此提高性能。
2.4 效率的提升策略之多频带(multiband)
部分主要涉及两篇文章:FeatherWave: An efficient high-fidelity neural vocoder with multi-band linear prediction 和An Efficient Subband Linear Prediction for LPCNet-based Neural Synthesis
原来的lpcnet主要对fullband部分进行预测,而该部分则是把fullband使用PQMF算法分成四个band,然后同时进行四个band预测。另外featherwave的sample rate network使用类似wavernn的高低8位预测,但整个架构为lpcent,因此也被归为该总结中。
首先,看一下multiband WaveRNN结构,知道什么叫做multiband合成,如下图所示。该声码器首先对音频进行分带,然后输入到WaveRNN,该WaveRNN每次输出不再是一个点,而是输出多个点,其点数由subband的个数决定(常分为4个频带,使用算法PQMF,如下图所示),最后进行merge band。(对于我这个非声学出来的学生,才接触语音领域两年,不太容易想出该方法)
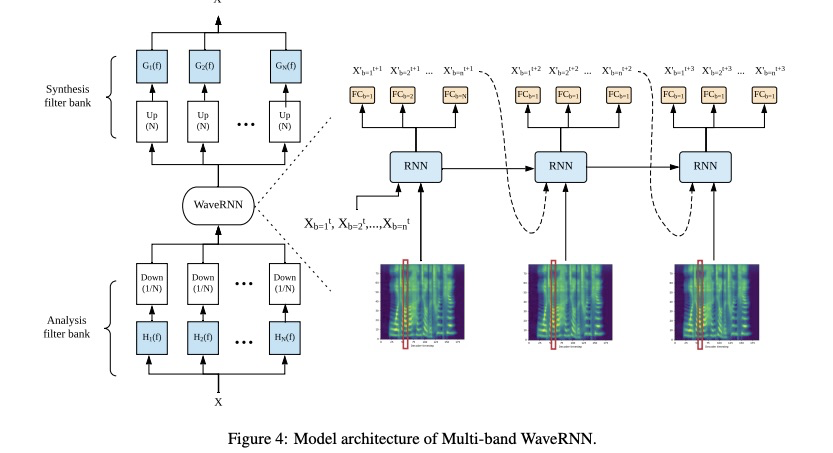
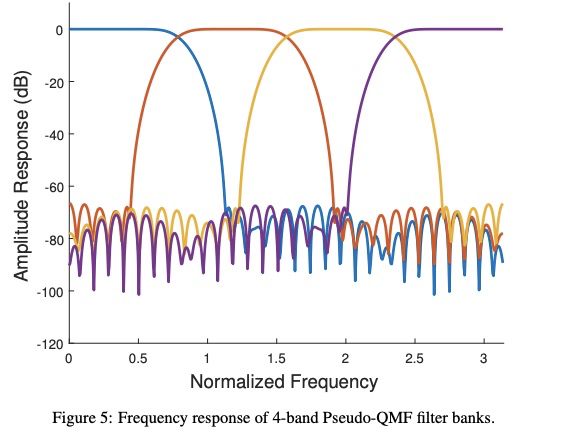
现在看一下featherwave这篇文章:具体的结构如下图所示,该系统架构跟原始的LPCNET相同,只是sample rate network变成了multiband,每次输出subband多个采样点。至于如何进行频带划分,可以参考QMF算法。另外,featherwave的公式变成multi-band linear prediction(MB-LP)。
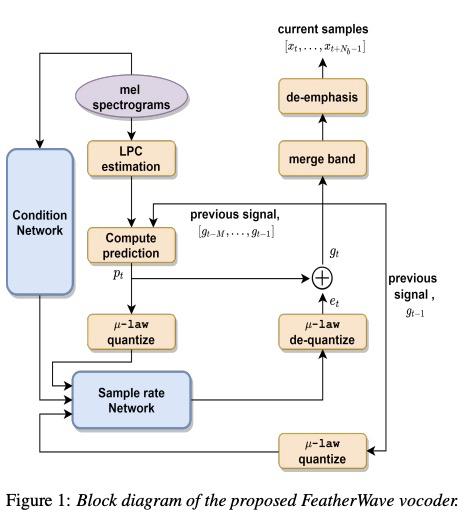
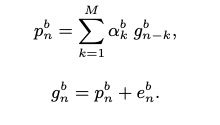
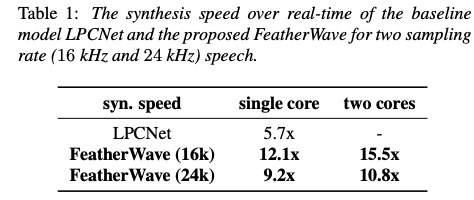
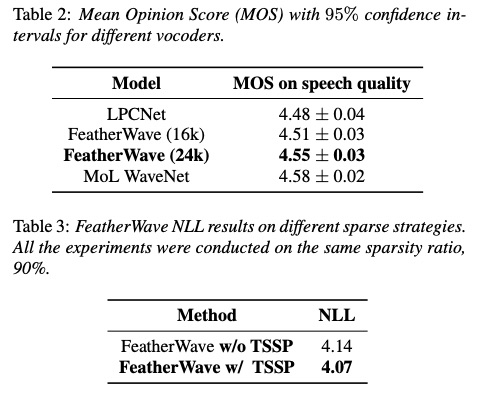
看一下featherwave的实验。首先,通过计算可得到FeatherWave时间复杂度为1.6GFLOPS,该值远小于现在的LPCENT 2.8GFLOPS。从实验结果可知:单核情况下,合成16k音频,FeatherWave合成速度是LPCNET的两倍多,24k的合成速度也几乎2倍(Table 1)。然后从MOS方面进行对比,FeatherWave的MOS比LPCNET稍高。
接下来看下文章subband lpcnet。很多使用multiband技术的文章都是假设被分的subband之间互不影响,因此可以同时进行subband的推理。而本文提出subband之间是存在相互作用关系,因此提出了相互作用的multiband自回归模型,使lpcnet的合成质量和推理速度都得到提高。首先看一下自回归的模型公式和子代公式,其中h为声学特征,两者的区别为每次推理4个点(划分为4个子带)
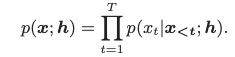
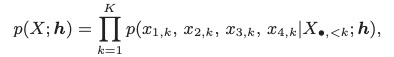
现有的multiband系统使用上边的公式,认为每个子代之间相互独立,但DSP技术提出每个subband之间存在很强的联系,因此本文提出了如下的多带联合分布公式

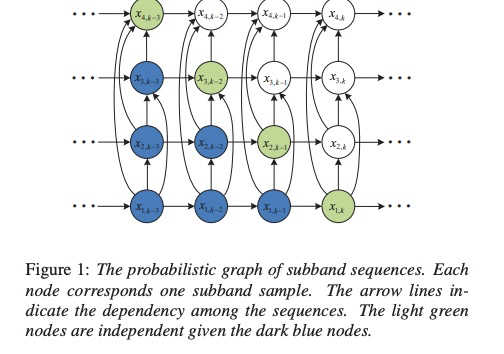
可能公式看起来很繁琐,可以看下图所示,fullband被分为4个子带,图中的点代表每一个采样点,箭头代表关联。当进行采样的时候,绿色点可以同时进行计算,因此达到多采样点的目的,这样设计是否很酷。
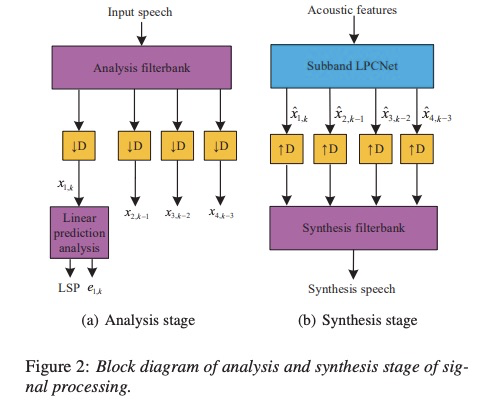
现在,讲一下该文章信号处理的两个阶段:分析阶段和合成阶段。分析阶段对fullband进行子代划分,然后求取第一个子代的lsp和激励e。合成阶段就是把声学特征经过声码器合成每个子带的采样点,然后进行整合成最终的时域波形。
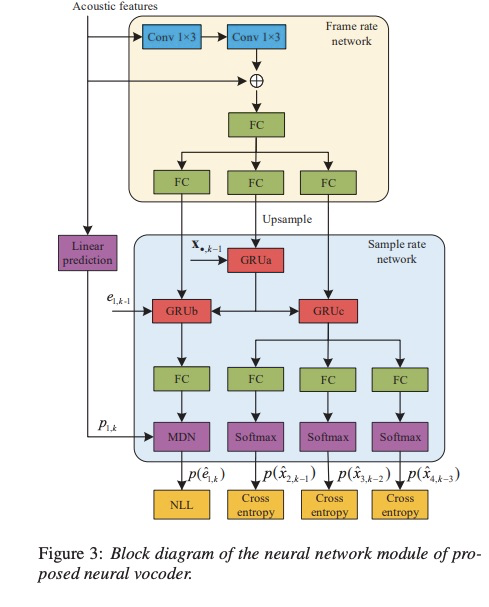
最后看一下该subband lpcnet声码器的设计图3。与原来的lpcnet不同的地方为frame rate network最后存在三个fc层,分别与sample rate network中的gru相对应。其中grua被四个子代共享,grub为第一个子代使用,gruc为其它三个子代共享 。然后,第一子带推理激励后使用计算出采样点,其它子带推理出采样点。(对低频刻画的更好)
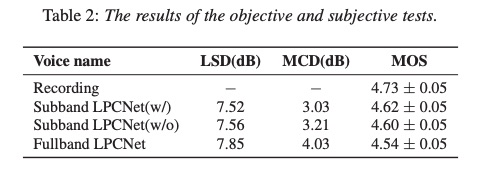
最后,我们看一下该文章实验结果。本文计算的复杂度为:wavernn 10GFLOPS, wavenet 100 GFLOPS, fullband LPCNET 3.5GFLOPS ,本文提出的subband LPCNET 为1.2GFLOPS,几乎速度比fullband lpcnet提高三倍。MOS测试方面,subband LPCNET(w/)为本文方案,subband LPCNET(w/o)为子带之间互不关联,由table 2可知,本文提出的方案MOS最高。
小结:multiband 方法也是使用DSP中的技术,感觉要想对声码器进行深度优化,必须系统的学习一下DSP技术,尤其像我这样才接触语音领域才两年的菜鸟。multiband的根本出发点也是同时生成多点,与multi-sampling不同的是,multi-sampling是共享时间开销较大的GRU层,而multiband是并行合成多点。
3 总结
lpcnet声码器兼具较低的复杂度和较高的语音合成质量两个优点,因此受到学术界和产业界的欢迎。近几年对其优化的文章也比较多,本文对这两年lpcnet的发展做个简单总结,希望给对该声码器感兴趣的同行有点帮助,节约大家的时间。至于这些技术的好坏,还需要读者通过试验亲身体会。
4 引用
[1] J. Valin and J. Skoglund, "LPCNET: Improving Neural Speech Synthesis through Linear Prediction," ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom, 2019, pp. 5891-5895, doi: 10.1109/ICASSP.2019.8682804.
[2] Hwang M J, Song E, Yamamoto R, et al. Improving LPCNET-Based Text-to-Speech with Linear Prediction-Structured Mixture Density Network[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 7219-7223.
[3] Popov V, Kudinov M, Sadekova T. Gaussian Lpcnet for Multisample Speech Synthesis[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 6204-6208.
[4] Vipperla R, Park S, Choo K, et al. Bunched lpcnet: Vocoder for low-cost neural text-to-speech systems[J]. arXiv preprint arXiv:2008.04574, 2020.
[5] Tian Q, Zhang Z, Lu H, et al. FeatherWave: An efficient high-fidelity neural vocoder with multi-band linear prediction[J]. arXiv preprint arXiv:2005.05551, 2020.
[6] Cui Y, Wang X, He L, et al. An Efficient Subband Linear Prediction for LPCNet-based Neural Synthesis[J]. Proc. Interspeech 2020, 2020: 3555-3559.
欢迎关注公众号:低调奋进
